サーバー運用によくある問題
「業務時間外の緊急対応」を50%削減!その秘訣とは
- テックプレッソ株式会社
- 所在地岐阜県岐阜市金宝町1-15 4F
- 設立2014年
- 業種情報サービス業
- 従業員数15名
- https://tecpresso.co.jp/
テックプレッソ株式会社は顧客のビジネスに欠かせないインターネット技術の導入を支援するエンジニアリング企業だ。中でもお客様のニーズに応じたサーバーの提案から構築、運用、保守までをワンストップで担うクラウドホスティング事業は同社の柱となっている。2016年、その運用と保守の要となる監視業務の改善に着手。監視システムの刷新とその運用の最適化を続け、顧客のサーバーの安定稼働はもちろん、自分たちのライフワークバランスの改善にまでつなげている。業務時間外の対応について、「目指しているゴールにはまだまだ遠いですが、実際、目標を掲げる前と比較すると半分くらいにはなっています」と語るテックプレッソCTOの坂之上氏にその秘訣を聞いた。
テックプレッソのクラウドホスティング事業
株式会社テックプレッソ
代表取締役CTO 坂之上 達成 氏
——事業について教えてください。
坂之上氏 10年前の創業時からお客様に提供しているクラウドホスティングサービスやWebアプリケーション開発、インターネットインフラコンサルティング、自社Webサービス「まとめて領収書」の提供などをしています。私自身がサラリーマン時代にSIerでサーバー担当をしていたこともあり、創業当時から実績を重ねてきたクラウドホスティングサービスが会社を支える主力事業となっています。
アメリカにも子会社があるので、拠点のある東海地方はもちろん、東京や海外にもお客様がいます。一番多いのはWebの制作会社様や開発会社様で、レンタルサーバーでは応えられない案件に対してお客様の要望に合わせてAWSやAzure、さくらのVPS(Virtual Private Server)、Akamaiクラウドなどを提案して、サーバーの構築から運用、保守までをワンストックで担っています。OSはLinuxを専門としています。
——御社にとって監視とは?
坂之上氏 監視はサーバーの提供と不可分なものです。弊社がサーバーの運用や保守に関わるビジネスをやっている限り監視を適切に行うのは絶対必要な、ビジネスの基盤と言えます。お客様のサーバーをお預かりしている以上、やるのが当たり前ですね。
Webサイトやメール、仕事を進める上で必要な各種Webサービスなど、我々がお預かりしているサーバーが提供するサービスが、常時動いていることに対するお客様の期待値はものすごく高いと日々感じています。やはりお客様からしたらこれらはインフラなんです。よく言われることですが、正常に動いていても「ありがとう」とは言ってもらえず、1分でも落ちると怒られるという笑。
そういったこともありメンバーには「何か問題が起きたら、お客様から言われる前に絶対にこちらから連絡しよう」と日々伝えて、それを実践しています。復旧を目指す前にまず報告しようと。お客様に先に問題を指摘されている時というのは、すでにお客様が不安になっている時なので、それでは遅いんです。逆に、こちらから「今こういうことが起きています」と報告すると安心いただけます。
こういったことも含めて、初動を早くするために監視は不可欠なものと考えています。
既存の監視ツールの運用に限界が
——導入前に抱えていた問題はどのようなものでしたか?
坂之上氏 創業当初はZabbixと自作の監視ツールの2つで監視していたのですが、一言でいうとそれらの運用が大変だったということになります。
新規のお客様にサーバーを提案して納めるといった売上を増やす業務に集中したいのに、監視ツールの運用という本業とは異なる業務に多くの工数を割いていたんです。
具体的には、
- アラートを通知する仕組みの開発とメンテナンス
- 2つの監視サーバーのパフォーマンスチューニング
- Zabbixの学習
の3つです。
これらは気軽に日常的にできることではなくて、本腰入れて丸一日時間を確保してやらないといけないような重たい仕事でした。
アラートには2つの問題があって、ひとつは、寝ている時でも起きて対応しないといけないのに起こしてくれる仕組みになっていないこと。もうひとつは、誤報です。誤報と言っているのは、監視元の通信障害で監視対象に異常がないのに、そのすべてのダウン通知が飛んできてしまうといった類のものです。
監視サーバーにはVPSを活用していたのですが、性能が足りなくなればチューニングが必要です。サービスが重くなった際の調査や「リソースが足りない」「データベースがパンクしている」といったことがわかった後の対応に多くの時間を費やしていました。
監視対象が増えれば、それだけデータベースに監視データが記録されていくので、それがパンパンになると監視自体が不安定になります。ゴミデータを掃除するといったデータメンテナンス作業も不定期に発生していました。
こうなると、「監視する基盤を監視しなくてはいけない?」となるのですが、それは明らかにおかしいですよね笑。監視は不可欠ですが、それが自分たちの仕事ではないはずなので。
さらに、会社が成長してメンバーが増えると、彼らが分厚い参考書を読みながら本業ではないZabbixの学習をしなければいけない。やっぱりおかしいなと。
絶対もっといい方法があるはずだと思い立って解決策を探しはじめたのが創業から2年ほど経った頃なので、8年前です。
——そして見つけたのがSite24x7ということですね。
坂之上氏 はい。どうやって見つけたかはまったく覚えていないのですが、当時は日本語に対応していませんでした。ドキュメントも英語でしたが幸い英語に対するアレルギーはなかったので、とりあえず社内にあったテスト用のサーバーにエージェントを入れて、設定も入れてみてどういう動きするのかなと検証しました。
電話の通知が簡単にできることに感動したのを覚えています。これで寝ていても起きれるじゃん!と笑。
——比較検討はしましたか?
坂之上氏 日本企業が提供するSaaS型のサーバー監視ツールを少し試しました。ただ、結構お高かったんです。
なのでほとんど比較はせず、これが良さそうだから試してみようと当時のメンバーとSite24x7を使い始めてそのまま根付いたといった感じです。
最初から多くの工数を割いて本気を出して使わなくても、とりあえずこのURLの死活監視だけやってみようとか、このサーバーのCPUの監視だけやってみようといったことが簡単にできたので。
その後、少しずつこれもできるあれもできるという感じで利用範囲が広がっていきました。
導入後に多発した業務時間外の緊急対応
——Site24x7を導入して先ほどの3つの工数問題は解消されましたか?
坂之上氏 はい。すべて解消されました。
アラーティングの仕組みは提供されていますし、監視サーバーもなくなりました。新しく入ってきたメンバーたちも少し教えるだけですぐに習得できています。
ただ、Site24x7を運用しているにもかかわらず、なぜか一時期、メンバーたちの時間外の緊急対応が多すぎるということがあったんです。毎晩毎晩何かの対応をしているなと。
肝は黄色の注意アラート
——監視をしていれば時間外対応は減らせるはずなのに?
坂之上氏 そうなんです。そこで調査したところ、アラートをスルーしていることが原因とわかりました。
Site24x7は、正常な状態を「緑」、注意を「黄色」、警告を「オレンジ」、ダウンを「赤」とステータスが4色でわかるようになっていますよね。アラートとしても記録されます。黄色とオレンジは段階的にしきい値を入れるわけですが、黄色の注意アラートをスルーしていたんです。
そこで今も重点的にみんなで取り組んでいるのが「取り逃しの防止」です。それは、注意アラートの対応ルールの明確化としきい値の最適化とも言えます。
アラーティングされているのにそれを無視していてはアラーティングの意味がないですよね。黄色が本当に黄色のまま放置されてもいいのだとしたらそれは緑ということです。なので、黄色も必ず何かしらのアクションをすべきレベルの値をしきい値に設定します。
例えば、黄色になったらお客様に報告して、リソースであればその増強の必要性について会話するなどのアクションです。しきい値はお客様によってもサーバーによっても異なるので定期的に見直しています。
一番起こりやすく、わかりやすい例がディスクです。
以前はオレンジになってからようやく動くということもあったので「3日後にディスクが枯渇してしまうので明日緊急対応します」となり、お客様にも「空き容量が非常に少なくなっています。どうしましょう」と連絡するようなことがありました。
それを黄色の時点で「今何パーセントまできています」と打診をはじめることで、例えば「このペースだと一か月後ぐらいに危なくなってきそうなので再来週くらいにちょっとディスク増やしておきましょうか」といった割と余裕のある話ができるようになります。
黄色のうちにトラブルの芽を摘むことを徹底できれば、オレンジの出番は極めて少なくなるはずで、この状態を維持することが監視改善目標の一つとなっています。
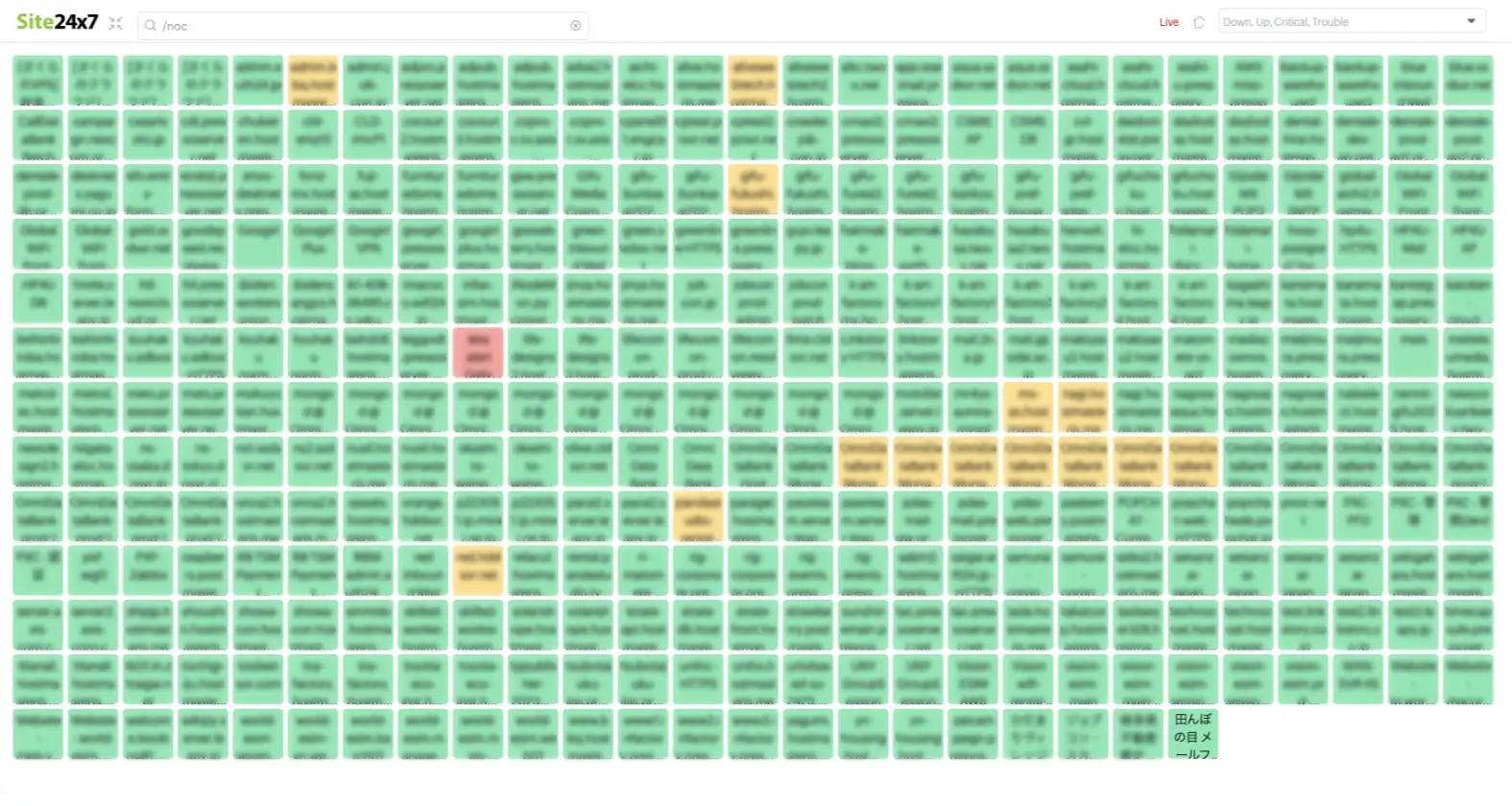
NOCビュー
坂之上氏は日常的によくこの画面を見ている。
——勉強になります。その結果、時間外の対応が減らせたわけですね?
坂之上氏 はい。目指しているゴールにはまだまだ遠いですが、実際、目標を掲げる前と比較すると半分くらいにはなっています。
平日の日中に黄色の対処をするだけで、業務時間外の緊急対応は機械が壊れるといった突発的なことを除けば必要なくなるというのが今目指しているゴールです。
——サーバー監視以外に使っている機能はありますか?
坂之上氏 ITオートメーションとメール配信監視を使っています。
ITオートメーションはふたつの使い方をしています。ひとつは一般的な使い方で、ダウンアラートが上がった際にサーバーを自動的に再起動させるというもの。もうひとつは裏技的な使い方で全サーバーの設定値の調査や脆弱性のチェックです。
前者は、あるお客様に「サーバーがダウンする原因はわかっている。それは直さなくていいからダウンしたらすぐに復旧してほしい」と言われたので、それなら再起動を自動化しましょうと提案しました。
後者は、ITオートメーションでアラートに応じてコマンドを実行できるわけですが、そのテスト実行ボタンを利用する使い方です。
例えば、cPanelサーバー向けにリリースされているApache Solrパッケージのcpanel-dovecot-solrがインストールされているサーバに対して、特定のセキュリティパッチが適用済みかどうかを判定する場合、こんなコマンドを用意して、Site24x7のエージェントの入ったすべてのサーバーに一斉に流します。
rpm -q cpanel-dovecot-solr; if [ $? -eq 1 ]; then echo "solr is not installed"; else rpm -q --changelog cpanel-dovecot-solr | grep CPANEL-39455; if [ $? -eq 0 ]; then echo "solr is patched"; else echo "solr is not patched"; fi; fi
このコマンドの出力は「solr is not installed」「solr is patched」「solr is not patched」の3種類で、「solr is not patched」が出力されたサーバーがパッチ未適用という意味になります。ITオートメーションログという実行結果画面を見て「このサーバーとこのサーバーは対応必要だ」とわかるわけです。便利ですよね。
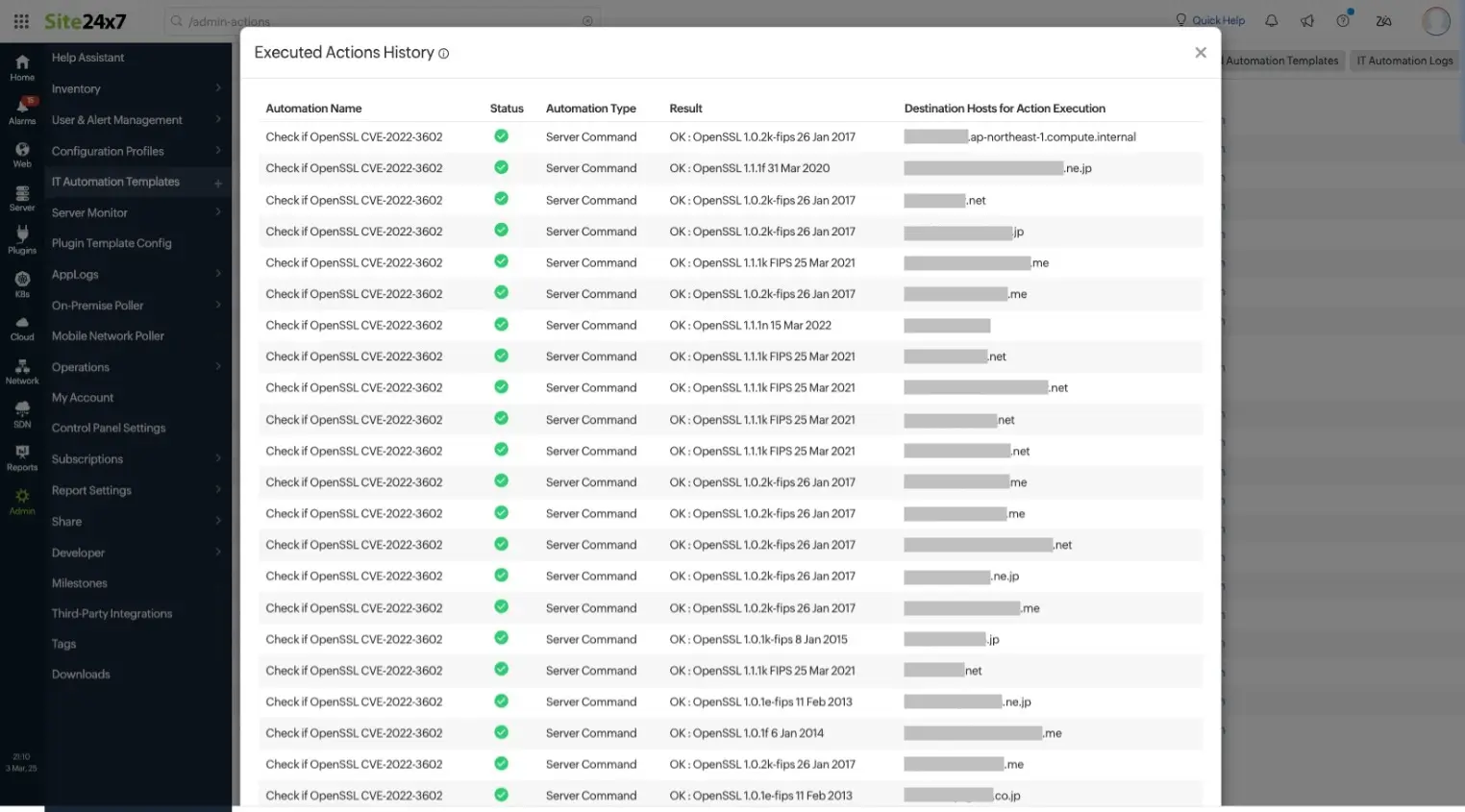
ITオートメーションログ
実行結果画面。この例では「OK」と出力されている。
毎月のように新たな脆弱性情報は出てくるものなので、これはITオートメーション機能とは別に、脆弱性チェック機能としてリリースしてほしいです笑。
メール配信監視は「田んぼの目メール」という学校や幼稚園、保育園、自治会向けのメーリングリストサービスの基盤の開発と運用を請け負っているので、そちらで使っています。
これは日常的な連絡網として広く活用されているサービスなのですが、災害や事件などが発生した際には緊急連絡網として一斉配信が行われたり安否確認機能が発動するので大量のメールが流れます。そんな時もメールが滞りなく発信されて、外部に流れて、遅延も起きていないといったことをSite24x7で定期的にチェックすることで把握できるようにしています。
必要以上の監視は組まない
——最後に、導入を検討している方へアドバイスをお願いします。
坂之上氏 これはゾーホーさんからしたら売上が小さくなってしまうのでつまらない話なのですが。
Site24x7の監視機能はとても充実していて多岐にわたります。ただし、それを必要以上に組まないことをおすすめします。
私もエンジニアなのでこういったツールを触るのは楽しくて最初はあれもこれもとたくさん組んでいたんです。そうすると当然アラートも増えます。先ほど話した無意味なアラートも増えて心臓にも悪い。だから、監視対象から見直すことにしました。
トライ&エラーを繰り返して私たちがたどり着いた結論は、自分たちに責任のある範囲だけを監視するということです。
私たちの場合は、主にWebの制作会社様や開発会社様向けにサーバーを提供しているので、URLの死活監視でダウンを検知した後に、サーバーの可用性とリソースに異常がないことを確認できればそれだけで「自分たちのテリトリーじゃないところで何か起きてる可能性が高いぞ」という判断ができるようになります。
その上で先ほどお話したしきい値やアラーティングの最適化を継続しています。 それらはすべて、自分たちが心穏やかに過ごせるようになるための工夫と言えます。
——ありがとうございます。大変勉強になりました。Site24x7は今、AIで不要アラートやしきい値チューニングの削減を目指しているのでご期待ください。
坂之上氏 そうなんですね。それは期待しています。