しきい値と可用性
監視メトリックデータが指定したしきい値を懲戒した際にアラートを発生させます。これによりパフォーマンス問題を特定することができます。
プラットフォームの可用性監視はリソースへのアクセシビリティを絶えず監視して、ステータス(アップ、ダウン、トラブル、クリティカル)を確認します。ステータスに変更があった際には、指定した形態で通知を行います。
このプロファイルは監視作成時にデフォルトで指定されます。
しきい値と可用性の追加
しきい値と可用性のプロファイルの追加方法は次のとおりです。
- Site24x7にログインします。
- [管理]→[設定プロファイル]→[しきい値と可用性]に移動します。
- 右上の[しきい値プロファイルの追加]ドロップダウンから[しきい値プロファイル]を選択します。
- 次の情報を入力します。
- 監視タイプ:ドロップダウンから監視タイプを選択します。
- 表示名:プロファイルの名前を入力します。
- ダウンと判定するまでのロケーション数:監視タイプがWeb監視の場合、監視をダウンとするロケーション数を選択します。
- しきい値の設定
しきい値の設定では次の項目に対して値を入力します。この項目は選択した監視タイプに基づいて、内容が異なります。- 条件:基準(<、>、=、<=、>=)を設定します。
- しきい値:しきい値とするパフォーマンスメトリック値を入力します。例として、CPU使用率、メモリ使用率、ネットワークレイテンシーなどがあります。上記の条件に対して値が判定され、違反の際はアラートを行います。
- ポーリングの計画:しきい値判定に用いるパフォーマンス値の要素を選択します。ポーリング数や発生時間などに監視単位を変更できます。
- ポーリング値:上記で指定した条件をいくつの連続監視データで判定するかを選択します。
- 通知:アラート発生時のステータスを選択します。条件の重要度によってステータスを選択できます。
5.1 AIベースしきい値:
AIベースしきい値により自動でしきい値を指定し異常なスパイクを追跡します。このしきい値を選択した場合、アノマリ重大度のステータスが反映されます。
-
詳細しきい値
詳細しきい値により、複数パフォーマンス属性(例:サーバーのCPUとプロセス)に対して条件付けしてアラート設定を行えます。&&(AND)と ||(OR)から各要素の条件付けを行えます。
例として、次の要素を「A &&(( B && C )|| D)」と条件付けしたとします。-
A:CPU使用率のしきい値 >80%
-
B:メモリ使用率のしきい値 >75%
-
C:ディスクI/O待機時間のしきい値 >60ミリ秒
-
D:アクティブプロセス数のしきい値 >200
単一条件内に複数回は使用できないですが、異なる条件に使用することはできます。例として、CPU使用率は単一条件内に複数回使用できないですが、2つの異なる条件内に使用できます。詳細しきい値設定で、ポーリングの計画、ポーリング値、通知、オートメーションは設定することができます。
-
トラブル、クリティカル、ダウンの3ステータスを設定できます。
-
各ステータスで1つの条件のみ設定できます。異なるステータスでの条件を追加したい場合、右側の[+]アイコンをクリックします。
-
詳細しきい値は監視レベルの属性にのみ指定可能で。子属性レベルには適用できません。
ユースケース
-
DevOpsチームでデータセンターを管理するチームは、不必要な拡張を防ぐために、リソース競合の兆候を特定する必要があります。詳細しきい値を使用して、CPU使用率80%とメモリ使用率85%を超過するか、スワップ使用率70%を超過した際に、アラートを受信できます。これによりリソース競合の早期検知を行うことができます。
条件:((a > 80 && b > 85) || c > 70%) -
高いリソース消費によりWebアプリケーションパフォーマンスの低下が発生した際、IT運用チームがCPU使用率85%とメモリ使用率90%の超過、またはディスク容量10%未満とネットワーク使用率が90%超過している場合に、クリティカルアラートを受信するように設定します。これによりパフォーマン問題について把握することが可能です。
条件:(a > 85% && b > 90%) || (c < 10% && d> 90%) -
システム障害の恐れがあるデータベースサーバーが存在する際にダウンアラートを受信したいとします。この場合システム管理者は、システムがオーバーロード状態である場合にダウンアラートを送信するように設定できます。CPU使用率90%超過、メモリ使用率95%超過、スワップ使用率90%超過の場合にのみアラートを送信すれば、システムに危険が及ぶ前にアラートを受信できます。
条件:(a > 90 && b > 95 && c > 90%)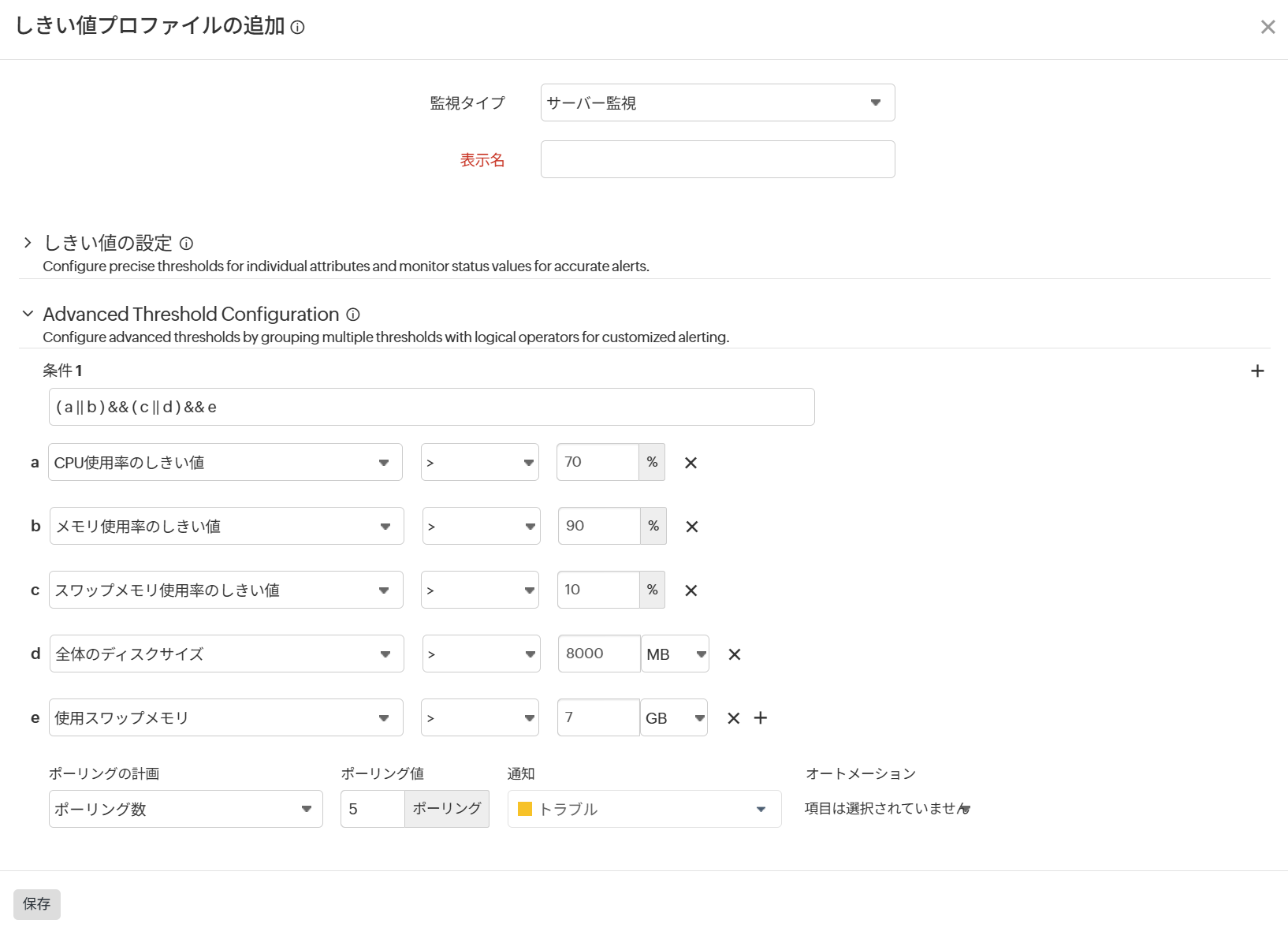
-
- [保存]をクリックします。
- 作成したしきい値と可用性プロファイルは、[管理]→[設定プロファイル]→[しきい値と可用性]のリストに表示されます。
しきい値と可用性の編集
- [管理]→[設定プロファイル]→[しきい値と可用性]に移動し、編集したいプロファイルを選択します。
- パラメーターを編集します。
- [保存]をクリックします。
しきい値と可用性の削除
- [管理]→[設定プロファイル]→[しきい値と可用性]に移動します。
- 削除したいプロファイルの右側のハンバーガーアイコンから[削除]を選択します。
- 開かれたポップアップで[削除]をクリックします。
ハンバーガーアイコンで表示される[複製]から既存のしきい値プロファイルの設定内容を複製して設定を行うことができます。
トランザクション監視
Webトランザクション | REST APIトランザクション | Webトランザクション(ブラウザー)
Web監視
Webサイト | Webページスピード(ブラウザー) | REST API | SOAP Webサービス | DNSサーバー | SSL / TLS証明書 | メール配信 | ポート(カスタムプロトコル) | POPサーバー | SMTPサーバー | Ping | FTPサーバー | NTPサーバー | FTP転送 | ISPレイテンシー
仮想化監視
オンプレミスポーラー | VMware ESX/ESXiサーバー | VMware VM | VMwareデータストア | VMwareリソースプール | VMwareスナップショット | VMwareクラスター
VMware VDI: Horizon
Nutanix: Nutanixクラスター | Nutanixホスト | Nutanix VM
Veeam:バックアップサーバー
AWS監視
EC2インスタンス | RDSインスタンス | S3バケット | S3オブジェクトURLエンドポイント | DynamoDBテーブル | Classic load balancer | Application load balancer | SNSトピック | Lambda | ElastiCache | Network load balancer | SQS | CloudFront | Kinesis services | Elastic Beanstalk | Direct Connect | VPC-VPN Connection | API Gateway | Route 53 Health Check | Route 53 Resolver | Route 53 Hosted Zone | Route 53 Hosted Zone Record Set | Gateway Load Balancer | Systems Manager | Amazon AppStream 2.0
サーバー監視
サーバー監視 | サーバー監視 - エージェントレス |プラグイン | Exchange | SQL | IIS | SharePoint | Office 365 | SMARTディスク
ネットワーク監視
ネットワーク装置 | NetFlow監視 | NCM装置 | VoIP監視 | WAN監視 | IPアドレス管理(IPAM)